Monitoring and Measuring MSMEs Activity From Social Media By Using BERT-based Event Extractor
Conference
64th ISI World Statistics Congress - Ottawa, Canada
Format: CPS Abstract
Keywords: "social, extraction, socioeconomic
Abstract
One characteristic of Indonesia's economy is the significant contribution of Micro, Small, and Medium Enterprises (MSMEs) toward the national Gross Domestic Product (GDP) and domestic economic activities. MSMEs as the backbone of Indonesia's economy, contributing to 60% of the national GDP and 96.9% of employment. Thus, it is necessary to monitor MSMEs' activities to ensure their health condition and continuous growth. This monitoring will enable the government and policymakers to take immediate action when MSMEs conditions decline, such as during the current pandemic and post-pandemic.
Social media contains a massive amount of information. A large number of discussions on social media are responses triggered by events. Several events correlate with MSMEs, either directly or indirectly. Words like "try this", "don't miss it", "order it", and "special promo" can be associated with the MSMEs Activity Event (MAE). However, extracting events from this corpus is quite challenging since the keywords used in the text have a large variety. Thus, we need the event extraction (EE) method to help both the extraction of intelligence information and computational experiments on the text.
In this research, we will use SpanBERT, a special variant of BERT designed to better represent and predict text spans. SpanBERT takes wider text portions by adopting a different masking scheme and training objective. During training, random contiguous spans of tokens are masked rather than individual words, forcing the model to predict the full span from the known tokens.
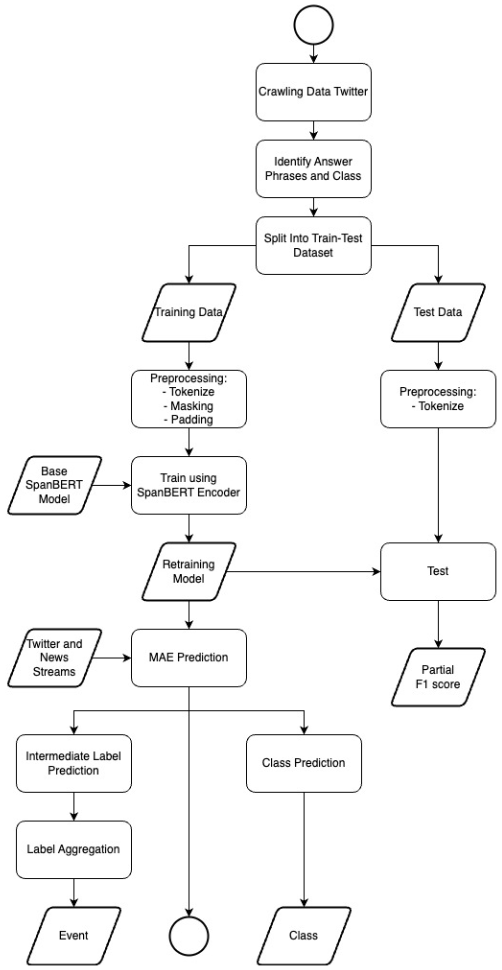
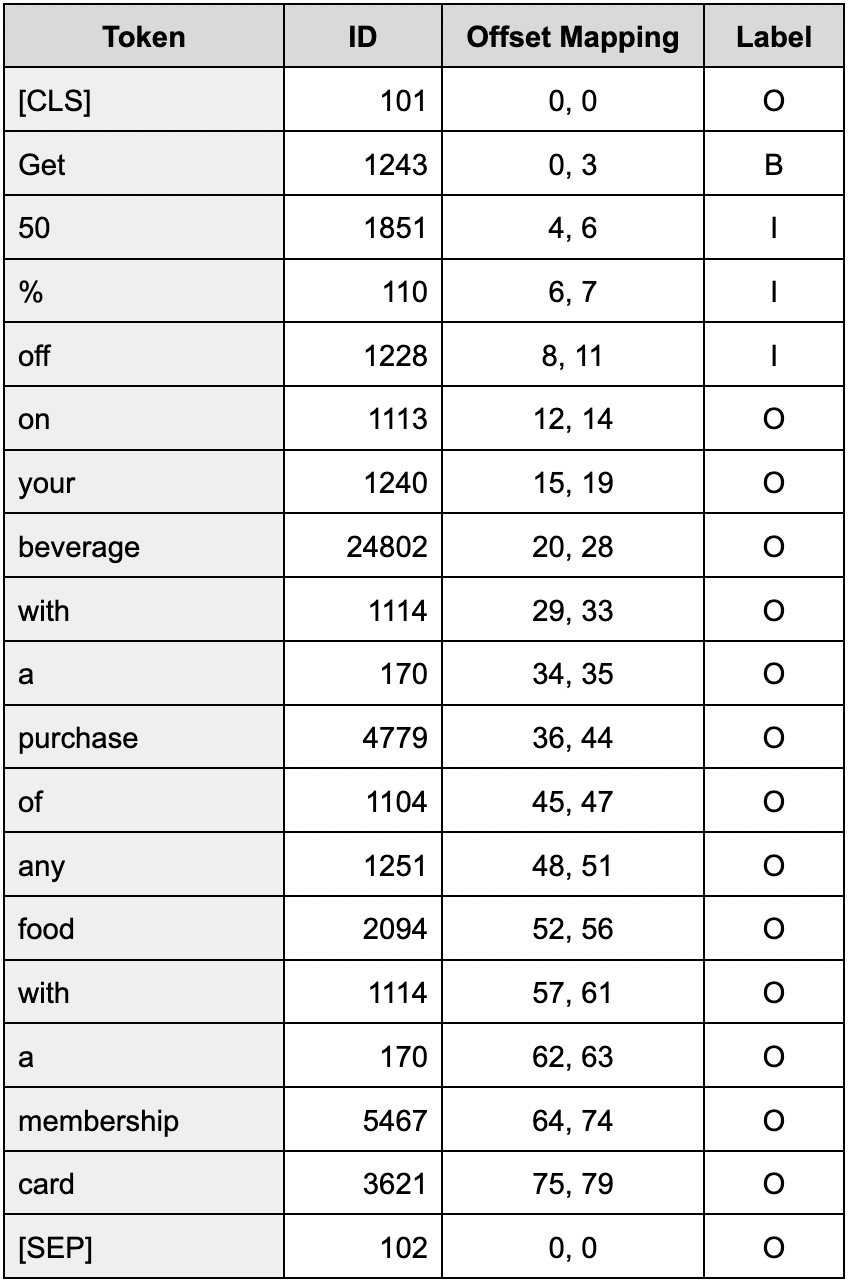
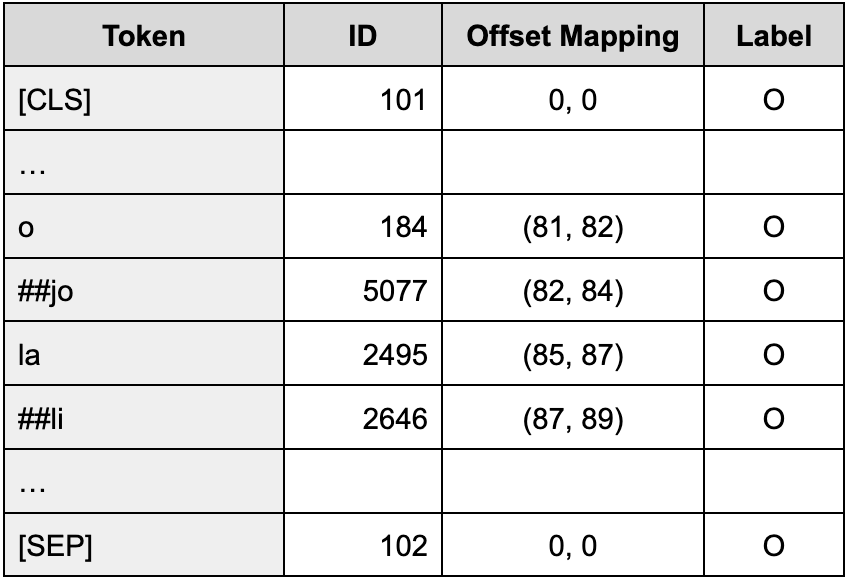
The dataset will be crawled from Twitter, Instagram, and news articles using either the Python Tweepy package. The crawling results are split into sentence levels. It is then manually labeled into two classes: a positive class represents the MAE, and a negative class represents the non-MAE. We will identify and select phrases from each tweet that can be labeled as MAE. Each training data is accompanied by offset mapping, a list of tuples that record the start and the end character of MSMEs Activity Event (MAE). To prevent "out-of-vocabulary, Wordpiece tokenization method is used. The special tokens are applied, which are a [CLS] (classification) token that marks the beginning of the sentence, a [SEP] (separator) token to mark the end of the sentence, and a [PAD] (padding) token to pad all sequences of sentences to the same length.
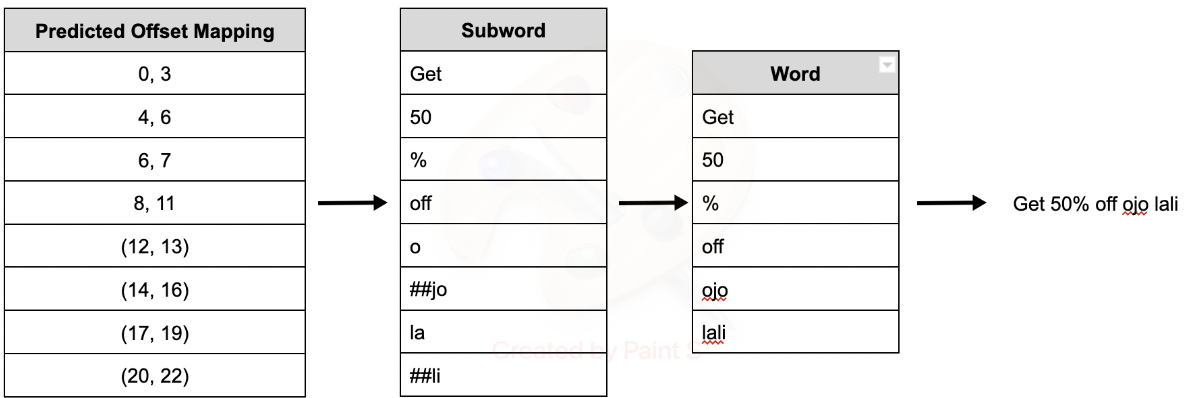
The training dataset is fed into SpanBERT neural network architecture which is composed of 12 encoder layers with a multi-head attention mask. The network takes the sequence of subword tokens as an input and outputs a sequence with the same number of embeddings. Each transformer (encoder) layer computes an intermediate embedding of each token. Then the attention mechanism allows the network to enrich the embeddings with contextual information after each layer. The subword-level predictions from the model need to be aggregated to produce word-level labels which can be easily mapped to the original input sequence. The aggregated output is a sequence of word-level BIO labels, which can be compared to preprocessed inputs or easily converted into character-level indices to produce predicted events.
Figures/Tables
Screen Shot 2022-11-23 at 22.58.50

Screen Shot 2022-11-23 at 22.59.12
Screen Shot 2022-11-23 at 22.59.35
Screen Shot 2022-11-23 at 23.00.03

Screen Shot 2022-11-23 at 23.00.18
Screen Shot 2022-11-23 at 23.00.49