Machine learning-based approach for imputing poverty rates in the Labor Force Survey in Morocco
Conference
64th ISI World Statistics Congress - Ottawa, Canada
Format: CPS Poster
Keywords: cross-survey imputation, machine learning, multiple imputation, poverty, random forest

Abstract
The estimation of poverty requires data on income or consumption expenditures, such data is generally collected by national statistics offices through Household Expenditure Surveys (known as HES). These surveys require a costly budget that statistical agencies cannot afford every year or within short intervals. Usually, such surveys are conducted every 4-7 years. Therefore, researchers find themselves in data upgrade constraint when there is a great need to update poverty indicators. On another side, the Labor Force Survey (LFS), which has a relatively lightweight questionnaire, is less costly comparing to HES. LFS surveys are conducted regularly every year and sometimes within quarterly intervals. They hold a rich source of information about households, namely economic and social status of households, demographics and living conditions. In addition, most of mentioned characteristics are considered as common sections in LFS and HES questionnaires.
The availability of LFS data, and the fatal relationship between households’ profile and welfare, have inspired researchers to capitalize these households’ characteristics in the purpose of estimating living standards including poverty estimation.
The objective of this study was to impute poverty rates in Labor force Surveys where the expenditures distribution is not available. We highlight two major stages to meet this aim: (i) Building the prediction model for the distribution of consumption expenditures on the basis of available information in LFS. (ii) Calculation of poverty rates by simulating multiple predictions on the basis of the model obtained in (i).
The methodology consisted in using predictive modelling in conjunction with multiple imputation. We adopted a machine learning approach to build models for predicting household’s consumption expenditures on the basis of data from LFS and HES 2014. We used cross-survey technique to impute consumption in labor force survey in the purpose of estimating poverty rate for periods when consumption distribution is not available.
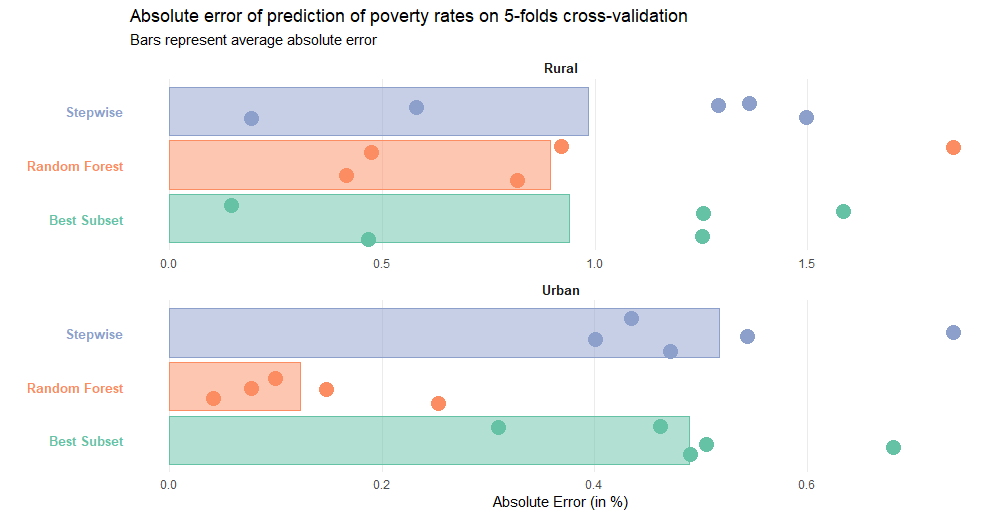
Two kinds of models were trained separately on rural and urban areas, linear models reveal a good prediction performance, but with over estimation, leaving suspicious bias in the estimation of proportion under poverty line. In contrast, random forest method yields better results especially in urban area.
Figures/Tables
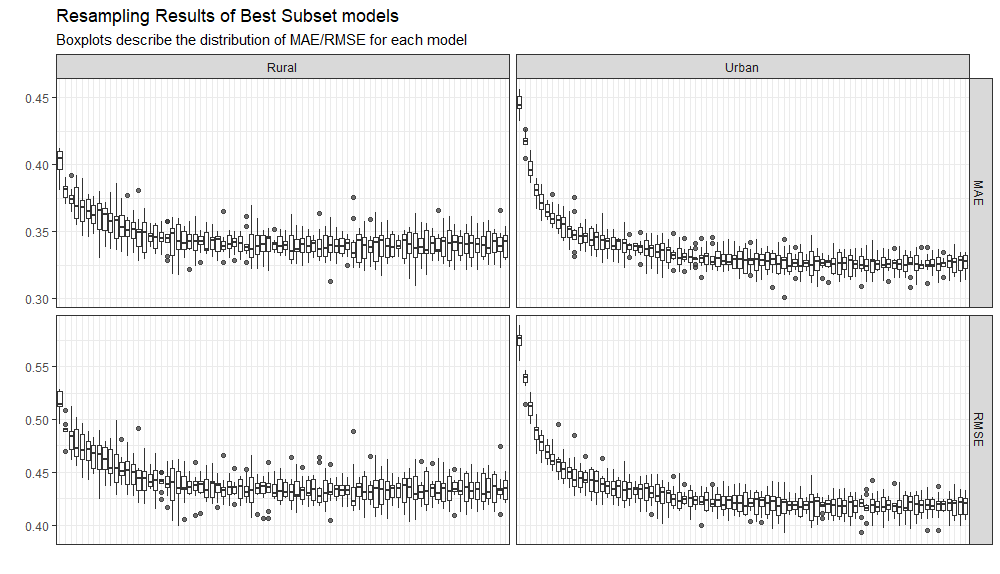
Resampling_best_subset
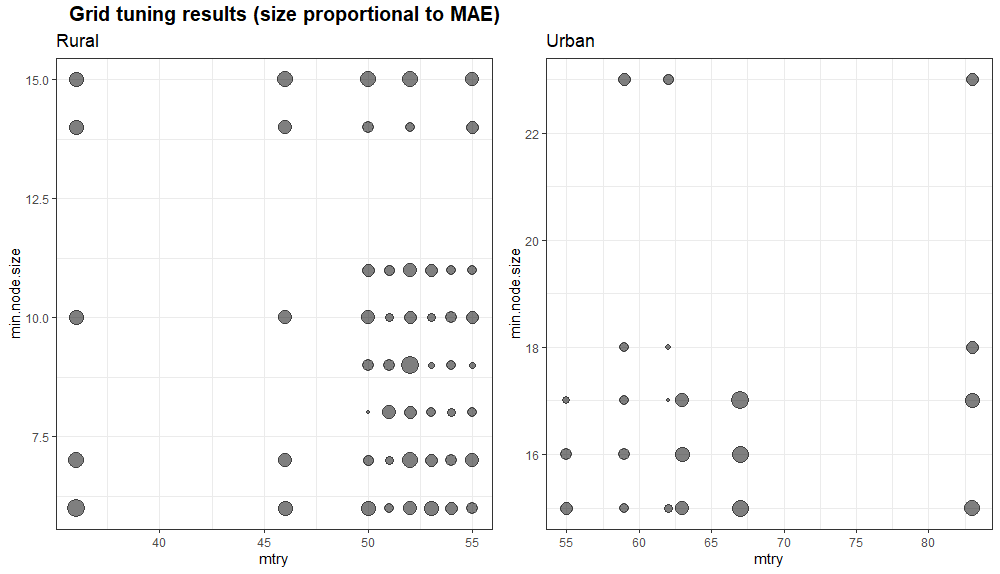
Tuning_RF
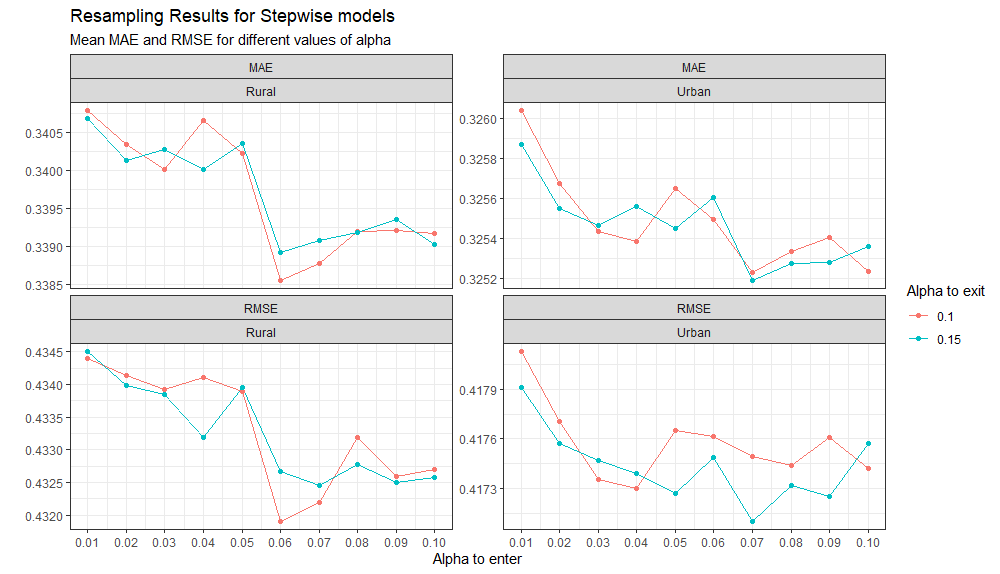
Resampling_Stepwise
predicted_vs_actual
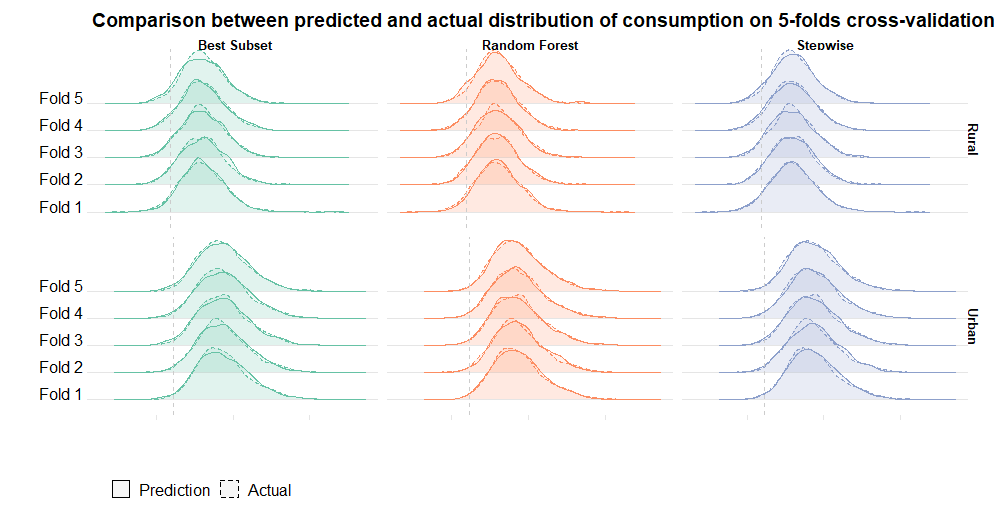
pred_vs_predicted_poverty
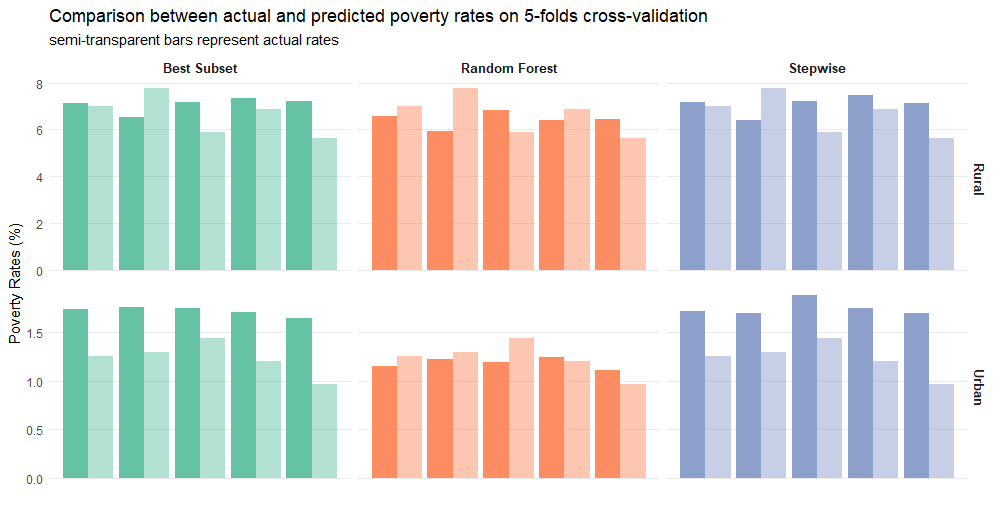
MAE_poverty